What happens when an AI agent iterates on browser tests overnight
March 2026 · Tomasz Borys
On the evening of 10 March 2026 I gave an AI agent a browser testing problem and left it to iterate. It ran 24 experiments over two hours. By midnight it had a 10/10 pass rate on a test that could not be reliably automated for over a decade. The validation run confirmed it again. 20 out of 20.
The test is simple to describe:
- Open the Jackpotjoy site
- Log in
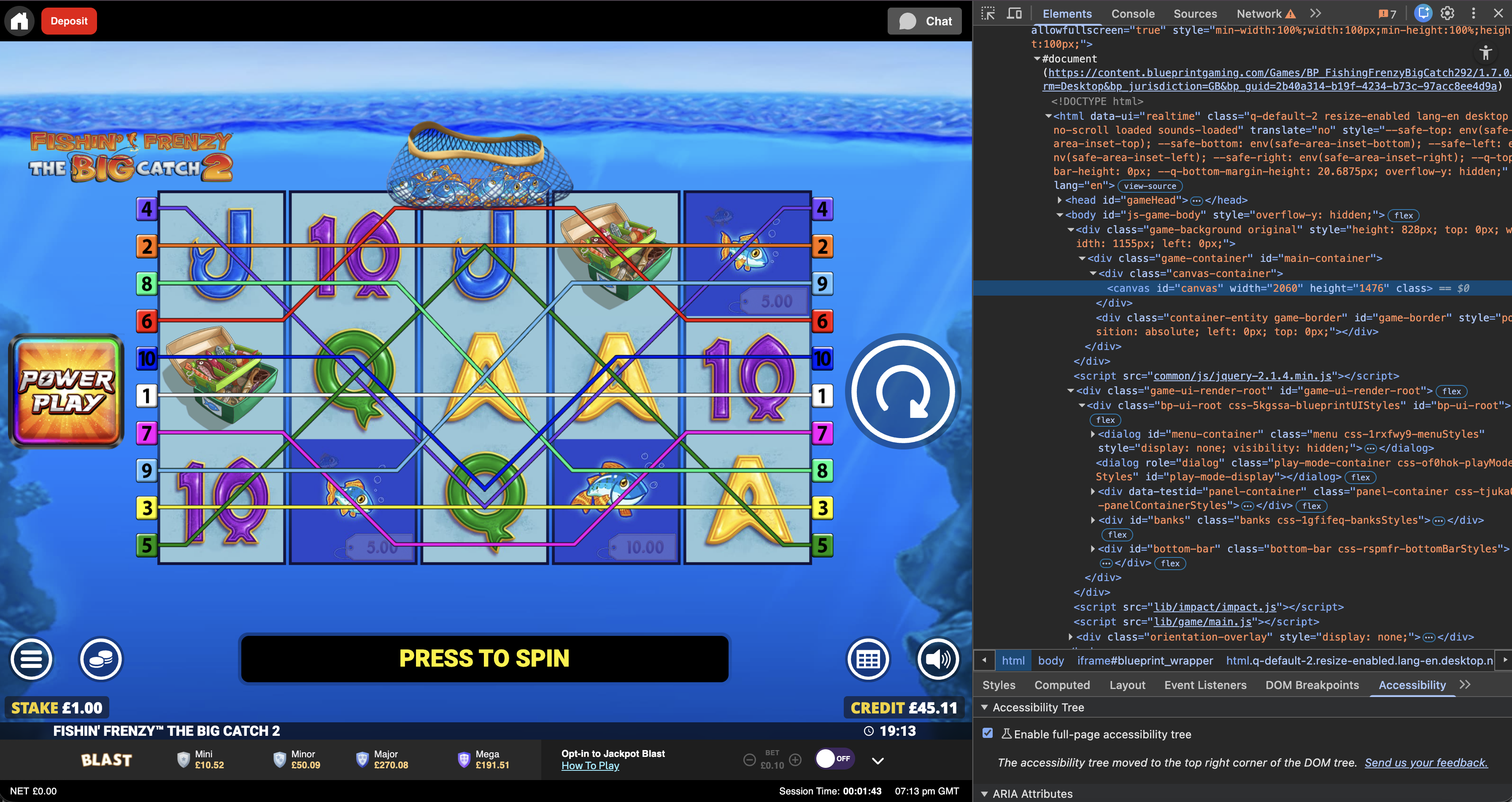
- Navigate to Fishin' Frenzy The Big Catch 2, a slot game
- Click the spin button
- Confirm the game responded
- Do it ten times
The spin button lives on an HTML canvas. Inside the canvas there are no useful DOM nodes, selectors or accessibility hooks to target. To a browser automation tool, the game is a single opaque rectangle. That is what makes it hard.
What made this interesting was not the game itself. The problem had the right shape for autonomous iteration: one bounded system, one measurable outcome, a fast feedback loop.
This problem goes back to 2013. Not as something constantly on my mind, but as one of those engineering challenges that never had a clean solution.
A decade of canvas
In 2013 I was a QA Automation Engineer at Gamesys. The job was to automate casino game testing with Selenium. Desktop web, mobile web, native apps. The team built frameworks to unify test flows across platforms. Appium for mobile. Selenium for the rest.
Canvas games were always the pain point.
The spin button was not a button. It was pixels painted onto a surface that Selenium could not inspect. No element to find. No click target to address. You could screenshot the canvas and look at it yourself, but the tool had no way in.
The iteration loops made it worse:
- Write a test
- Run it
- Wait
- Check the result
- Fix something
- Repeat
Each change cost minutes. The pre production environment was unstable. Login would go down mid session. Ten minutes lost before discovering the environment was the problem, not the code.


The non canvas parts worked well. Login, navigation, deposits. But the canvas interaction stayed manual. Unsolved.
In March 2025 there was another attempt. The tooling had changed. Browser Use, an open source AI testing framework, could drive Playwright with an LLM making decisions from screenshots. GPT-4o could look at a canvas and identify the spin button visually. A hybrid approach in Python seemed promising: scripted Playwright for login and navigation, AI agent for the canvas interaction.
It worked just enough to be interesting and not enough to be dependable. GPT-4o could find the spin button in a screenshot. But translating "I can see it" into "click at these coordinates" was unreliable. The pass rate bounced between 1 in 10 and 5 in 10. Non deterministic. Prompt sensitive. Slow. It got parked.
What changed
In early 2026, Andrej Karpathy published autoresearch. The idea is straightforward. Give an agent a clear objective with measurable good/bad criteria. Let it run unsupervised. When a change improves the metric, commit. When it does not, revert. The git history becomes a lab notebook of what worked and what failed.
Autoresearch was built for ML research. But the pattern maps directly onto browser testing. The metric is obvious: pass or fail. The criteria are binary. The feedback loop is fast. The right shape for an autonomous agent.
The sandbox took about twenty minutes to set up, whilst catching up with the backlog of Netflix TV shows. Together, Claude Code and I wrote the strategy prompt for the agent session that would run the experiment loop. The setup was simple: Claude Code orchestrated the experiment loop, Playwright controlled the browser, Gemini 3.1 Pro handled vision through an internal gateway and the whole thing ran in TypeScript rather than the Python setup I had tried the year before.
The experiment reduced to three files. program.md was the strategy, written once with Claude Code, describing the problem, the metric and the constraints. test.ts was the Playwright test that the agent rewrote across experiments. vision-prompt.md told the vision model what to look for in screenshots. The agent rewrote that too.

The strategy was written. The agent did the execution.
At 22:16 the first experiment ran. 0 out of 10. The agent could not even log in. Over the next experiments it fixed login selectors, dismissed cookie banners and found the game iframe. By experiment 3 it had switched to proportional canvas coordinates and replaced click() with a manual mouse sequence, passing 3 out of 3 attempts (smaller sample to iterate faster). By experiment 6 it was hitting 5 out of 5 with proper wait times between actions. By experiment 7 it scaled to the full 10 attempts and hit 8 out of 10, with two failures from an unhandled bonus round. By experiment 8 it handled bonus rounds. 10 out of 10.
The table below shows the committed experiments. Many more ran between these but were reverted because they did not improve the pass rate. That is the pattern working as designed: only improvements survive.
| Experiment | Pass rate | What changed |
|---|---|---|
| 1 (baseline) | 0/10 | Could not log in |
| 2 | 1/3 | Found spin button at proportional canvas coordinates |
| 3 | 3/3 | Replaced click() with move/down/up mouse sequence |
| 4 | 1/3 | Split "ready" vs "result" vision states |
| 5 | 1/3 | Added overlay dismiss and bonus detection |
| 6 | 5/5 | Individual clicks with 2s waits instead of rapid fire |
| 7 | 8/10 | Scaled to 10 attempts, found bonus round gap |
| 8 | 10/10 | Added fish picking clicks for bonus mini game |
| Validation | 10/10 | Second run confirming stability |
At 00:20 the validation run confirmed it. 10 out of 10 again. The agent had been left running deliberately, without the temptation to intervene. The results were there in the morning.
What the agent figured out
None of the following was taught. The agent found each through iteration.
Canvas clicks need decomposition. In this case, a standard Playwright click() was not reliably registered by the canvas game. The agent discovered that mouse.move(), then mouse.down(), then mouse.up() with 100ms pauses between each step is what the game engine actually registers.

The vision model was more reliable for classification than localisation. The 2025 attempt failed because the model was asked to locate the spin button. The agent learned to hardcode proportional coordinates for clicks and use the vision model only for state detection. "Is the game showing PRESS TO SPIN or GAME OVER?" is a question a vision model answers reliably. "Where exactly is the spin button?" is not.
The spin button is not where the label is. The text "PRESS TO SPIN" sits in one position. The actual clickable area is elsewhere on the canvas, at roughly (0.906, 0.519) proportionally. The agent found this by trial and error.
Focus matters. The game iframe needs a click on the canvas centre before it accepts input. Without that initial focus click, every subsequent action fails silently.
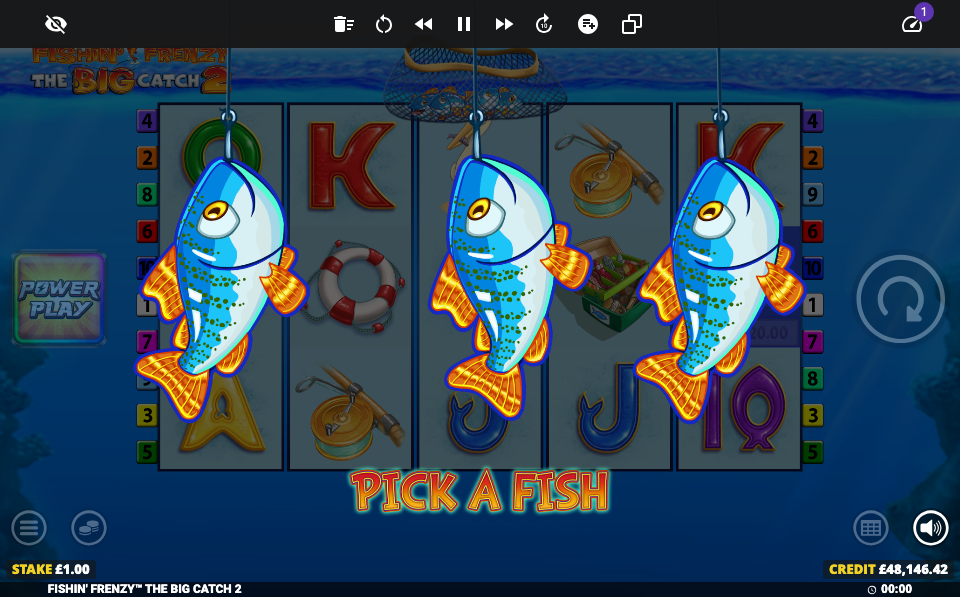
Bonus rounds are a different game. Fishin' Frenzy sometimes triggers a bonus round with a "PICK A FISH" mini game. The agent learned to detect this state and handle it with a specific click sequence before returning to the main test flow.
Two seconds is the wait time. Too short and the state check happens before the game responds. Too long and the test is slow. The agent converged on two seconds between action and verification across all experiments.
The pattern, not the demo
Canvas game testing is a niche problem. The pattern behind it is not.
Any task with a clear metric, a fast feedback loop and a bounded scope is a candidate for this approach. Build times. Test reliability. Configuration tuning. Performance budgets. The human writes the strategy. The agent runs the experiments. Git tracks what worked.
In a previous post about using AI tools across distributed systems, the observation was that agents hit a wall at runtime and ownership boundaries. The problem was unbounded. The agent could not access production metrics, talk to the team that owned the downstream service, or reason about organisational structure.
This experiment sat on the other side of that boundary. The problem was bounded. One page. One game. One metric. The agent could iterate without needing context it could not access.
Closing reflection
The decade of knowing why this problem was hard turned out to be the most valuable input. Not the code. Not the tooling. The understanding.
A strategy file written at 22:00, an agent left running, and two hours of autonomous iteration produced what would have taken days of manual trial and error. The git log tells the full story: 24 experiments, each with a commit message explaining what changed and why.
The pattern is worth trying if you have a problem with a clear metric and enough context to write the strategy. That context is not optional. A generic prompt would have produced generic results.
For bounded problems like this, the higher leverage work is writing the strategy, not staying inside the execution loop.
If you have ideas on where this pattern could apply, or want to discuss it further, I am on X and LinkedIn.